
Thunk you very much!
(or: How do OpenMP Compilers Work? Part 2)
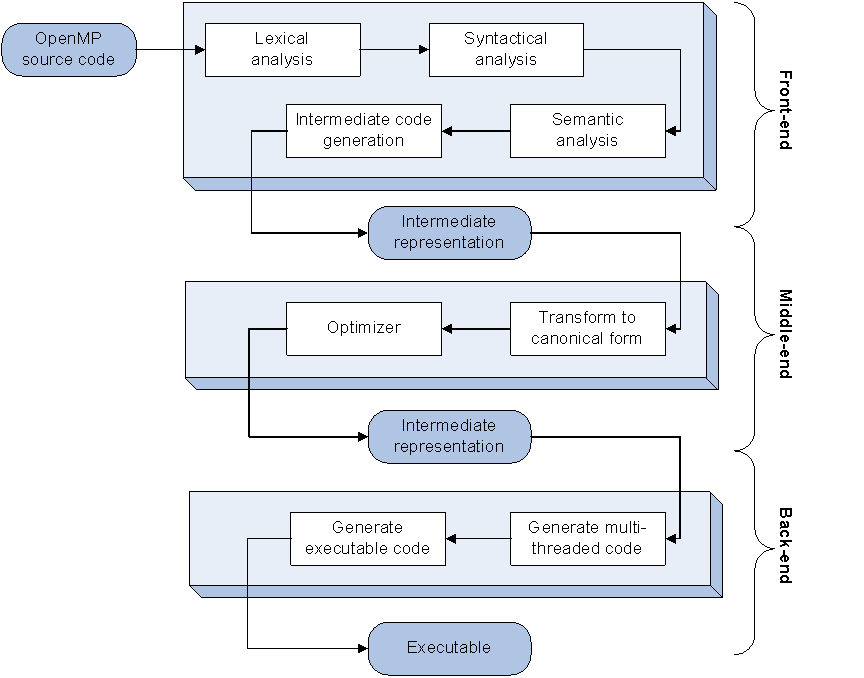
In the previous article, I have described how OpenMP source code is processed by an OpenMP compiler. OpenMP compilers resemble the typical compiler pipeline of traditional compilers and augment it with OpenMP-specific stages and passes that transform OpenMP code to multi-threaded execution (see also the picture below as a reminder). In this article, we want to explore how a parallel construct is transformed into code that can be handed over to a team of threads for execution. The focus will be on how to utilize POSIX threads, but the concepts shown here can easily mapped to other threading APIs as well.
Before we dive into the OpenMP low-level transformation to create threaded code, we first need to investigate how most threading APIs work to understand why these code transformations are necessary. Without too much loss of generality, we will start with a short example of how to concurrently execute a piece of code with a threading model such as POSIX threads. (Other threading APIs rely on similar concepts to implement threading.) I believe this is a good kick start for all that are not experts in low-level thread programming.
Let’s assume we want to write a POSIX version of the all-time favorite “Hello World”. Here’s the sequential code:
#include <stdio.h>
int main(int argc, char** argv) {
printf(“Hello World\n”);
return 0;
}
The following code fragment shows the POSIX version of the previous program. Each thread will print the “Hello World” string and then exit:
#include <stdio.h>
#include <pthread.h>
#define NUM_THREADS 8
void* run(void* arg) {
printf("Hello World\n");
return NULL;
}
int main(int argc, char** argv) {
int i;
pthread_t threads[NUM_THREADS];
for (i = 0; i < NUM_THREADS; i++) {
pthread_create(/*1*/ &threads[i], /*2*/ NULL, /*3*/ run, /*4*/ NULL);
}
for (i = 0; i < NUM_THREADS; i++) {
pthread_join(/*1*/ threads[i], /*2*/ NULL);
}
return 0;
}
Multi-threading with POSIX relies on a so-called start routine that contains the code to be executed. A typical task for enabling a sequential program for POSIX threads thus is to move the corresponding code from the sequential code area to a newly created thread function. In the above example, we have moved the printf statement from the main method to a newly created function called run. This function is required to accept one pointer that points to the arguments for the invocation and it returns a pointer to point to the address for the function’s return value.
To execute the run function in a new thread, we invoke the POSIX call pthread_create in a for loop to create a set of the thread. We pass along four arguments to pthread_create: (1) a pointer to the thread handle that can be used by the creator to control its created child threads, (2) a pointer to thread attributes (we can ignore this here), (3) a function pointer of the start routine (the run function in our case), and (4) the pointer that will be passed to the start routine as the argument. After the for loop is done, there are NUM_THREADS threads that will run concurrently in addition to the very first thread that executes the main function of our program.
At the end of the “Hello World” example, we need to take care to wait until all threads have finished executing their work. We use the pthread_join call for this purpose. It suspends the calling thread until a second thread has finished execution. The second thread is determined by the thread handle that is passed as the first argument of pthread_join. The second argument is a pointer to variable that will receive a pointer to a return value
That’s a lot of pointers and a lot of headache to get it right for more complex examples than “Hello World”. Higher level threading models (such OpenMP, Intel(R) Threading Building Blocks, etc.) are successful because they hide the technical details from the programmer and even provide a portable interface for different low-level threading APIs. Here’s the same “Hello World” program written with OpenMP:
#include <stdio.h>
int main(int argc, char **argv) {
#pragma omp parallel num_threads(NUM_THREADS)
printf(“Hello World\n”);
return 0;
}
An OpenMP compiler would transform this code example into the following code fragment (C-like pseudo-code) in the code generation phase for multi-threaded code:
void main_omp_func_0() {
printf(“Hello World\n”);
}
int main(int argc, char **argv) {
_omp_start_parallel_region(main_omp_func_0);
main_omp_func_0();
_omp_end_parallel_region();
return 0;
}
As one can see, the OpenMP construct in the main function has been replaced by calls to the OpenMP runtime system and that a new function has been created with the code of the OpenMP construct. The created function is called a thunk and corresponds to the start routine that we have seen in the POSIX threads example above. Sometimes the process of creating the thunk is called outlining (the reverse operation of inlining) and the thunk is then referred to as outline.
The two runtime functions _omp_start_parallel_region and _omp_end_parallel_region take care of all the administrative threading stuff that needs to be done internally. The call to _omp_start_parallel_region creates the team of threads, does some magic to satisfy OpenMP requirements (e.g. setting meaningful values for OpenMP’s “internal control variables”), and hands over a pointer to the thunk for execution in the created worker threads. Some implementation might also choose to use a thread pool to speed-up the launch of a parallel region. In this case _omp_start_parallel_region wakes up sleeping threads and tells them to execute new code. Similarly, _omp_end_parallel_region tears down parallel execution by terminating the threads (or putting them to sleep in the thread pool), and cleans up internal structures to prepare the OpenMP runtime for execution of the next parallel region.
It is worth to point out that the compiler usually leaves a call to the thunk between the start and end calls of the runtime system. OpenMP requires that the thread that encountered the parallel region participates in the parallel region as the master thread. This is most easily accomplished by just letting the encountering thread also execute the thunk and let the OpenMP runtime system use (n-1) additional threads only.
When it comes to data scoping, the thunk gets a little more complex. The translation techniques applied are still straightforward and easy to understand. Let’s look at the following example code:
#include <stdio.h>
int main(int argc, char** argv) {
int sh1 = 42;
int sh2 = 43;
int pr = 44;
int fp = 45;
int rd = 0;
#pragma omp parallel shared(sh1, sh2) private(pr) firstprivate(fp) reduction(+:rd)
{
printf("sh1=%d sh2=%d pr=%d fp=%d\n", sh1, sh2, pr, fp);
rd = 1;
}
printf(“rd=%d”, rd);
return 0;
}
This example translates to the following thunk code:
void main_omp_func_0(void *sh, int fp) {
int pr;
int rd = 0;
printf("Data: sh1=%d sh2=%d pr=%d fp=%d\n", ((int*) sh)[0], ((int*) sh)[1], pr, fp);
rd = 1;
_omp_reduce_add_int(address_of(sh[1]), rd);
}
To satisfy OpenMP’s specification, the compiler must assign shared storage to variables sh1 and sh2, private storage to variable pr, and private storage with an initial value for fp. For the shared storage the compiler might re-use the addresses of the shared variables on the stack or allocate a shadow copy in a shared storage area. The compiler assigns each shared variable a unique number to identify its address in the shared storage. As each thread maintains its own private stack for function local variables, private variables can be mapped to function local variables in the thunk function. In case of a firstprivate variable, the compiler needs to create a function local variable and add an initialization statement to set the firstprivate variable’s value.
The reduction variable rd is compiled like a private variable, with two key differences. First, the thread-private copy of rd is initialized with a default value that depends on the operation given at the reduction clause. For the addition operator, this default is equal to zero. Second, the compiler adds a new statement at the end of the thunk that takes the thread-private partial results and reduces the partial values with into a single global value. To store the global value, the original variable rd in the sequential scope is made an implicitly shared variable.
The transformations shown in this article give an idea on how the code is conceptually translated from sequential code with OpenMP pragmas into multi-threaded code. There is much headroom for improvements. OpenMP compilers typically do not create an explicit call to the reduction function, but utilize assembly instructions to atomically update variables in memory by adding a value. Other compilers might not create thunks for parallel regions, but instead do machine-dependent magic that executes code in-place on multiple threads.
In part 3 of this series, we will gain some insight into how an OpenMP compiler translates parallel for loops.