
The Thing from another World
(or: How do OpenMP Compilers Work? Part 1)
At the face-to-face meetings of the OpenMP Language Committee are frequently discussing many technical details of how to implement new features. I don’t know how many OpenMP users actually know about what a compiler does with their OpenMP code when it compiles the program. I wrote a series of blog articles that give a brief insight into the inner workings of an OpenMP compiler. I will keep everything on a rather high level and will not expose any implementation details of existing OpenMP compilers. All you’ll find are generic compiler techniques that can be used to translate an OpenMP-enriched program to machine code. This may help you as an OpenMP programmer to better understand limitations of OpenMP and the performance behavior of your OpenMP application.
If you find yourself familiar with low-level multi-threaded programming, e.g. with POSIX threads, Windows threads, or the Java Thread API, you will recognize all the patterns that I will describe in this series. It is the OpenMP compiler’s task to automatically do the same kind of transformation to map an OpenMP program to a threading library such as POSIX threads.
The following picture shows a typical compiler pipeline from a very high level. Most compilers will have a by far more complex pipeline with a variety of intermediate steps that are needed to perform all the optimization and transformation steps that we are all used to. To not overwhelm anybody with a highly complicated compiler pipeline, I left out all the intermediate steps and only focused on the main steps needed for the compilation pipeline.
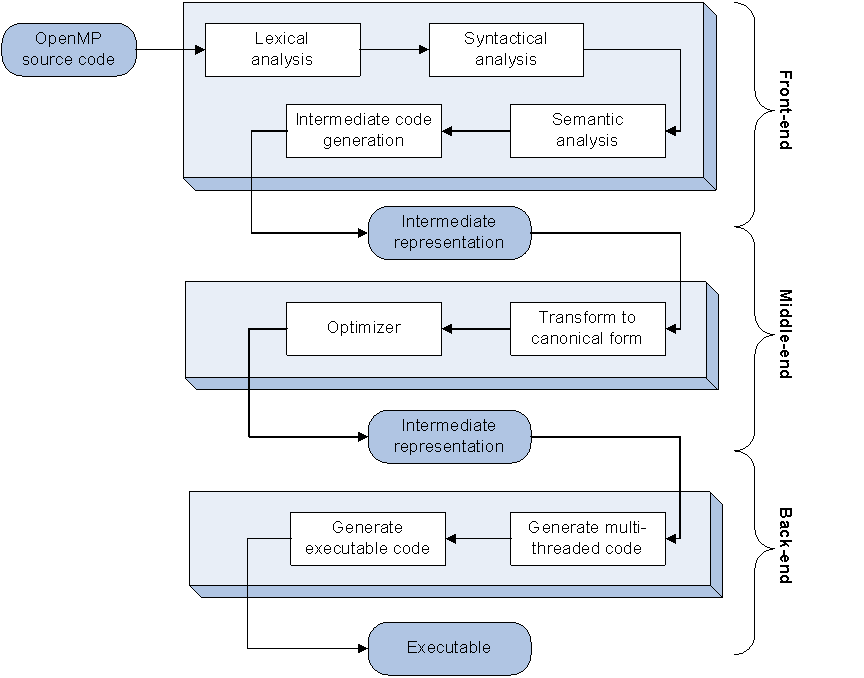
Modern compilers are typically divided into two main compiler stages: the front-end and back-end. Let us ignore the presence of the middle-end in the figure for now, we will come back to it later when we are talking about compiling an OpenMP program. Separating compilers into a front-end and a back-end greatly simplifies implementation of compilers that support more than one programming language and compilation target. Instead of n x m implementations (with n being the number of programming languages and m being the number of compilation targets), you one only needs to implement n front-ends and link them to m back-ends, which gives n+m compilers. The compiled program is passed from the front-end to the back-end in an intermediate language, a language-independent representation of programs.
The compiler front-end performs all tasks that depend on the programming language compiled. It reads in the source code, divides the stream of characters into tokens (e.g. the tokens “int” “a” “;”), and checks for syntactical correctness of the source code. The following semantic analysis ensures that everything is defined correctly. The front-end finally transforms the input program into a program in the compiler’s intermediate language and feeds the generated intermediate program into the back-end for further processing. Depending on the back-end, the intermediate language can still contain high-level constructs (e.g. loops, conditional statements) or may be close to assembly with only branch instructions and other low-level instructions.
The back-end takes over the intermediate program from the front-end and lowers it from the high-level intermediate representation to assembly for the compilation target. During this process, the back-end typically performs various optimizations. Most compiler front-ends follow a rule-directed compilation approach that leads to the creation of sub-optimal code paths. In addition, a programming language’s high level of abstraction also leads to sub-optimal code. For example, in array-based programs the same address calculations are performed redundantly. It is the back-end’s responsibility to optimize the code accordingly. It removes redundant code and replaces sub-optimal code with better performing code. Dead code elimination, function inlining, loop unrolling, vectorization, auto-parallelization are only a few optimizations that happen in this compiler stage. After all optimizations have been finished the program is transformed to assembly code and written to an object file for the linker.
Let us now come back to the middle-end. The middle-end takes care of all the OpenMP-related work that needs to be performed in an OpenMP compiler. I have to note that not all compilers run through such a middle-end stage. Some compilers merge the middle-end with the front-end and do all the OpenMP-related transformations in the front-end on the syntax tree of the program. Some compilers move the tasks of the middle-end into the back-end and implement transformations on top of the intermediate representation. But let’s keep the notion of the middle-end and see how it transforms OpenMP programs.
In an OpenMP compiler, the front-end is extended to analyze OpenMP directives in the code and to add the directives to the intermediate representation of the program. It would be possible for the front-end to create an intermediate program with threading calls and pass it to the back-end. However this would severely limit the back-end’s ability to analyze and optimize the OpenMP code and is therefore avoided in most compilers. The OpenMP-enriched intermediate program is passed to a middle-end that performs OpenMP-specific transformations and optimizations. We will now look at the code transformations of the middle-end in more detail.
OpenMP defines an extensive set of parallelization hints that programmers can add to their programs. OpenMP 3.0 defines 15 OpenMP constructs (e.g. parallel, for), not counting compound constructs (e.g. parallel for) and the various clauses (e.g. schedule) that can be added to the constructs. OpenMP 4.0 and 4.5 added several new directives for SIMD programming and offloading, which further increases the complexity of the code transoformations required. Clearly, this approach will not work out that well for a compiler writer.
So, as a first pass, the middle-end reduces the number of different constructs that need to be supported in code generation, by transforming the OpenMP program to a canonical form. Mapping the OpenMP constructs and directives to normal form saves the back-end from dealing with a lot of special cases and simplifies the templates for code generation. In its simplest form, the canonical form reduces the number of OpenMP constructs to 11, with headroom to further reduction. The middle-end also optimizes the placement of OpenMP constructs and directives to make the OpenMP program more efficient. A common optimization is to remove superfluous barriers by merging barriers or adding nowait clauses to constructs.
The following example shows how a worksharing construct may be translated to canonical form. The compiler has separated the compound parallel for construct, added a scheduling clause, and avoids an unneeded barrier at the end of the for construct by adding nowait to it.
|
void before(void) { int i; #pragma omp parallel for for (i = 0; i < LARGE; i++) { // do something } } |
int after(void) { #pragma omp parallel #pragma omp for schedule \ for (i = 0; i < LARGE; i++) { // do something } } |
Another good example of reducing complexity is the replacement of the OpenMP sections construct with a for loop. For each section construct, one case block in a switch statement on the loop counter is created. The loop iterates over the number of section constructs and is distributed amongst the threads by the added for construct.
|
void before(void) { #pragma omp parallel sections { #pragma omp section { // code fragment 1 } #pragma omp section { // code fragment 2 } // ... #pragma omp section { // code fragment N } } } |
void after(void) { #pragma omp parallel { #pragma omp for \ for (int __tmp = 0; __tmp < N; switch(__tmp) { case 0: // code fragment 1 break; case 1: // code fragment 2 break; // ... case 2: // code fragment N break; } } } } |
After the middle-end has finished its transformations and optimizations, the OpenMP-enriched intermediate code is handed over to the back-end for optimization and code generation. As the OpenMP constructs are still visible in the intermediate representation, the back-end can exploit several properties of an OpenMP program. For instance, private and firstprivate variables can easily be kept in registers as they are not visible to other threads. In addition, sophisticated algorithms like hierarchical data flow analysis may analyze the parallel code together with its surrounding sequential code to ease traditional compiler optimizations on the parallel code.
Finally, the back-end generates executable code from the OpenMP intermediate code representation. It first splices out the code of OpenMP constructs into new functions that are executed by the OpenMP threads at runtime. It then augments the sequential code with calls to the OpenMP runtime system to launch and control parallel execution. Part 2 of this series will show how these functions are created by the compiler and how they interact with the OpenMP runtime system.